
The way Large Language Models (LLMs) interact with the vast world of data sources and APIs (Application Programming Interface) is undergoing a significant transformation, thanks to the emergence of the Model Context Protocol (MCP). MCP servers act as a crucial middleware layer, a kind of "universal translator," designed to standardize and simplify how LLMs connect to and utilize external information. This protocol streamlines the integration process, freeing developers from navigating complex, often proprietary requirements specific to each LLM platform and data source.
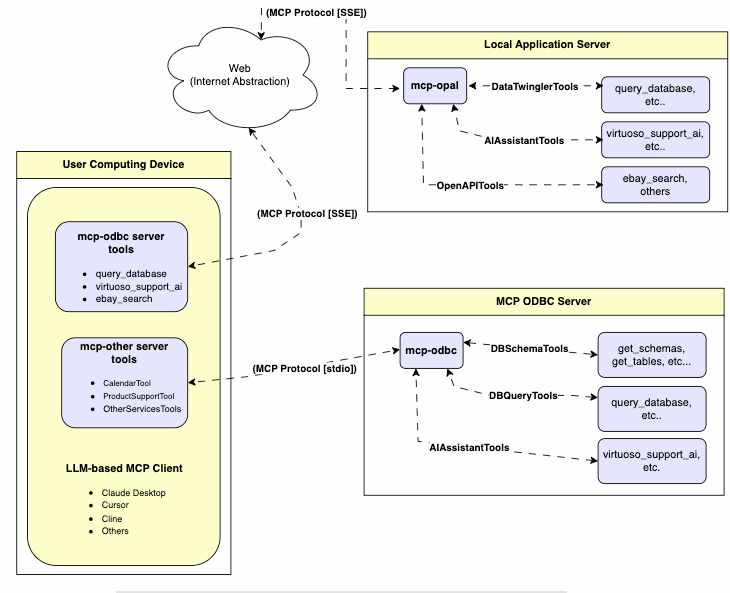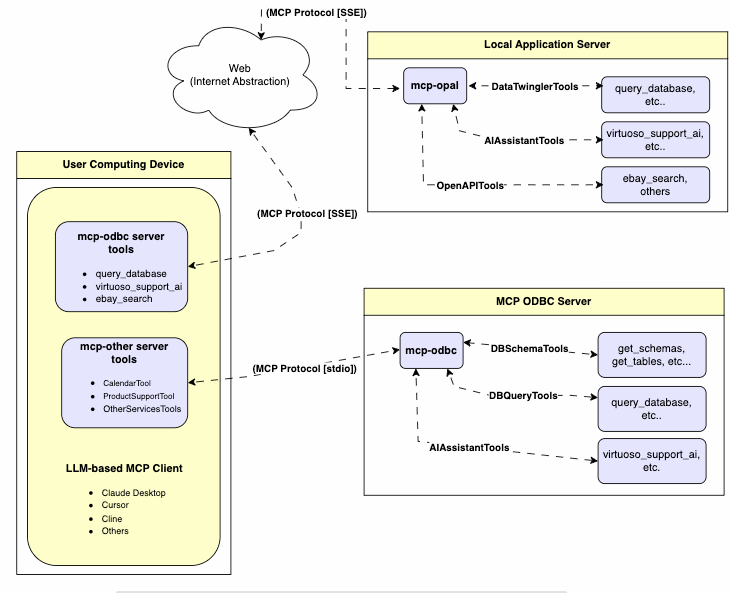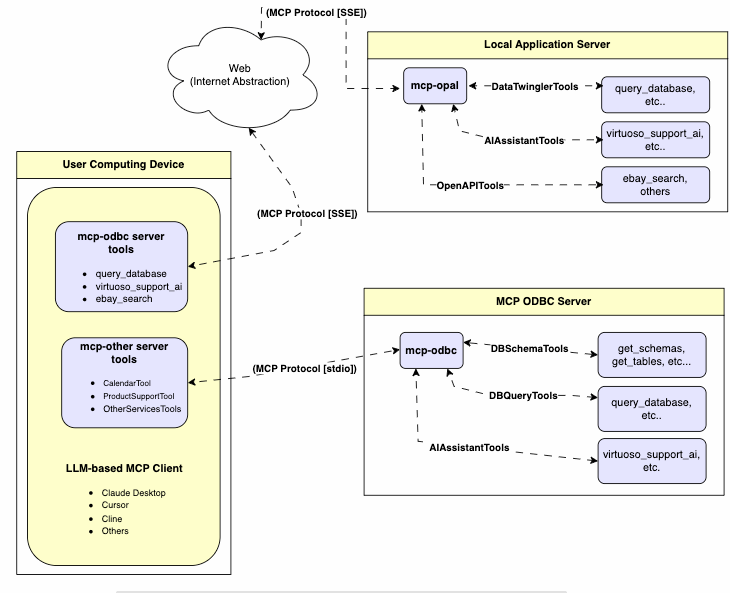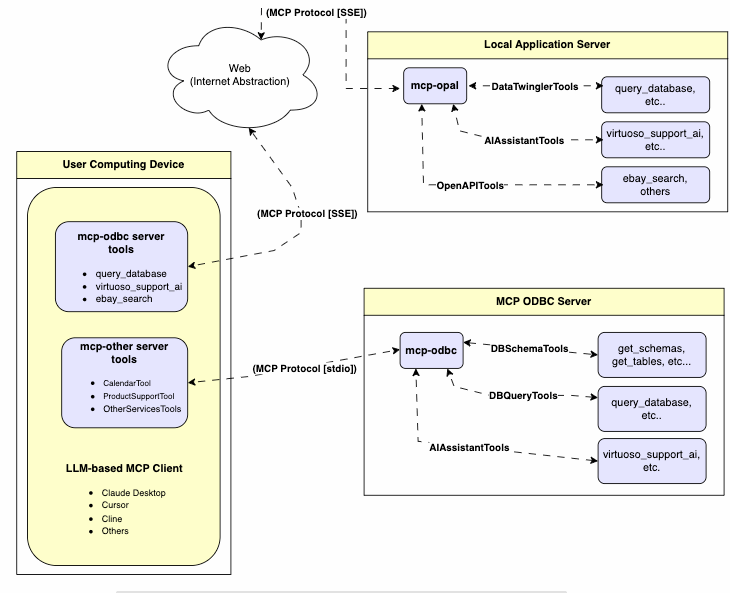
Understanding the Architecture: Analogies with ODBC and CORBA
MCP aims to create a more loosely coupled ecosystem for AI agents. It shares conceptual similarities with established technologies:
Like CORBA (Common Object Request Broker Architecture): MCP involves a system architecture with Request Brokers (realized via MCP client SDK components) and loosely coupled Request Agents (MCP servers). The client SDK provides libraries for discovering and interacting with available Request Agents, while the server SDK provides libraries for implementing Request Agents.
Like ODBC (Open Database Connectivity): MCP, from a data access perspective, offers a standardized way to connect to diverse data sources. You build a client application using MCP SDK's client components (akin to an ODBC Driver Manager), and on the server side, developers create specific MCP servers (akin to ODBC Drivers or Connectors) for different data sources using a variety of APIs (e.g., connectivity APIs offered by DBMS vendors).
Once these client and server components are in place, the protocol provides the mechanisms for clients to bind to and invoke operations on remote tools (exposed via the MCP servers). Crucially, MCP leverages modern infrastructure like HTTP (Hypertext Transfer Protocol) servers and authentication mechanisms (e.g., OAuth). This means the architecture doesn't mandate a specific transport protocol; interactions can occur over standard input/output (stdio), Server-Sent Events (SSE), HTTP, or even custom transports implemented by specific MCP servers.
After decades of evolution in middleware and distributed computing, MCP represents a significant step towards enabling seamless interaction between AI agents and the distributed services available across the Internet and the Web, amplified by recent LLM innovations.
Introducing the Open Source MCP Server for ODBC
A practical implementation highlighting the power of MCP is our new open-source MCP server for ODBC. This server enables transparent integration of data from any ODBC-accessible data source directly into Retrieval Augmented Generation (RAG) processing pipelines. RAG enhances LLM responses by grounding them in relevant, retrieved information, and the MCP server for ODBC makes accessing this information significantly easier.
Leveraging the multi-model Virtuoso platform's ODBC Driver for the reference implementation unlocks further advantages:
Broad 3rd Party DBMS Access: Connects to a wide array of databases (like Oracle, SQL Server, PostgreSQL, MySQL, etc.) through Virtuoso's virtual database layer, which is designed to work with various vendor ODBC drivers.
SPARQL Integration: Enables querying Knowledge Graphs using SPARQL, either directly via the MCP server or nested within SQL queries.
Cross-Platform Support: Works across Windows, macOS, and Linux environments.
Why is MCP Important?
Simplified Development: Reduces the complexity of connecting LLMs to diverse data sources and actions (operations, functions, procedures) via standardized client SDKs and server implementations.
Standardization & Interoperability: Provides a consistent protocol, promoting easier integration between different LLM clients and tool-providing servers.
Transport Flexibility: Supports various communication methods (stdio, SSE, HTTP, custom), adapting to different deployment needs – one size certainly doesn't fit all!
Enhanced RAG: Facilitates easier access to relevant data for grounding LLM responses in RAG pipelines.
Broader Data Access: Opens up relational databases (via ODBC), knowledge graphs (via SPARQL), filesystems via WebDAV, and actions (via APIs).
Enabling Loosely Coupled Agents: This architecture is fundamentally the right approach for an open standard aimed at enabling loosely coupled agentic interaction and orchestration workflows. It moves away from monolithic, siloed systems towards more flexible AI agent architectures.
Platform Independence: Agents built using MCP are not confined to a single LLM platform. For instance, AI Agents created via the OpenLink AI Layer (OPAL), which leverages these principles, are usable not just within specific environments like CustomGPTs, but also via interfaces like Claude Desktop, Cursor, command-line tools Cline, and many others.
Leveraging Existing Infrastructure: Builds upon established standards like ODBC, JDBC (leveraging existing ODBC to JDBC Bridge Connectors) and concepts from decades of middleware development.
Unleashing the vision behind the Semantic Web Project: Enabling interaction with Knowledge Graphs both within enterprises and across the vast Linked Open Data (LOD) Cloud collective where graphs are constructed using hyperlink-based identifiers (URIs/IRIs) in line with Linked Data Principles.
MCP represents a crucial step towards realizing the potential of loosely coupled AI scaled to the vast connectivity provided by the Internet and Web, making it easier to build powerful, agentic solutions by bridging the gap between LLMs and the world's data, information, and knowledge through a standardized, flexible, and open approach.
Screencast Demonstration
Getting Started with the MCP Server for ODBC
While specific steps depend on your LLM platform and environment, here’s a general guide to leveraging our MCP Server for ODBC:
Install MCP Client: Obtain an MCP-compliant AI Agent/Assistant (e.g., Claude Desktop, Cursor, Cline, or others).
Identify Your Data Source: Determine the database or data source you need your LLM to access (e.g., PostgreSQL, SQL Server, a Virtuoso instance).
Ensure ODBC Access: Verify that an appropriate ODBC driver is installed and configured on the machine where the MCP server will run, allowing connection to your target data source.
Deploy the MCP Server: Obtain and deploy our mcp-odbc-server (or mcp-sqlalchemy-server) open-source MCP Server for ODBC. Configure it with the connection details (e.g., DSN or connection string) for your ODBC data source(s).
Configure Your LLM/Agent: Set up your LLM application (using the MCP client components) to communicate with the deployed MCP server endpoint. Provide the necessary information to formulate requests (e.g., specifying the target data source and the query).
Formulate Queries: Structure your interactions so the LLM can request data via the MCP client, which then communicates with the MCP server. This could involve generating SQL or SPARQL queries.
Integrate into RAG: Use the MCP connection as a primary tool for the "Retrieval" step in your RAG pipeline.
Note: Refer to the specific documentation of the MCP SDK and the open-source MCP Server for ODBC project for detailed installation, configuration, and API usage instructions.
Tools Provided by the MCP for ODBC Server
get_schemas -- List database schemas accessible to connected database management system (DBMS).
get_tables -- List tables associated with a selected database schema.
describe_table -- Describe a specific table associated with a designated schema.
filter_table_names -- List a selection of tables associated with a selected database schema.
execute_query -- Execute a SQL query and return results in JSONL format.
execute_query_md -- Execute a SQL query and return results in Markdown format.
spasql_query -- Execute a SPARQL inside SQL query.
sparql_query -- Execute a SPARQL query.
virtuoso_support_ai -- Execute stored procedure for passing prompts on to LLMs supported by the OpenLink AI Layer (OPAL).
FAQ (Frequently Asked Questions)
Q1: What is the Model Context Protocol (MCP)?
A: MCP is a protocol designed to standardize and simplify how Large Language Models (LLMs) connect to and interact with external data sources and APIs, acting as a middleware or universal translator.
Q2: How is MCP different from standard API function calling in LLMs?
A: While function calling allows LLMs to use external tools via specific API definitions, MCP provides a standardized protocol and architecture (client SDKs, servers/agents) specifically for these interactions. This promotes interoperability and simplifies usage across different tools and LLM clients, offering features like standardized connection management and transport flexibility.
Q3: What is the MCP Server for ODBC?
A: It's an open-source implementation of an MCP server (or "agent" or "driver" in the analogy) specifically designed to connect LLM clients (using the MCP protocol) to any data sources and procedures (e.g., SQL Stored Procedures) that are accessible via an ODBC driver.
Q4: Do I need Virtuoso to use the ODBC MCP Server?
A: No, the server can work with any standard ODBC driver. However, using the Virtuoso ODBC driver provides additional benefits like simplified access to multiple backend databases and integrated SPARQL query capability.
Q5: What kinds of data sources can I connect to with the ODBC MCP Server?
A: Any data source for which you have a functioning ODBC driver (most relational databases, etc.). With Virtuoso, this extends to Knowledge Graphs via SPARQL. This might also include JDBC-accessible data sources accessible via ODBC to JDBC (Java Database Connectivity) bridge connectors.
Q6: How does MCP help with Retrieval Augmented Generation (RAG)?
A: MCP provides a standardized and efficient channel (via its client/server architecture) to retrieve information from databases or knowledge graphs during the retrieval step of the RAG process.
Q7: Is MCP replacing ODBC?
A: No. MCP draws inspiration and shares architectural characteristics but serves a different purpose – specifically facilitating LLM interaction with external systems in a standardized way. It leverages existing technologies like ODBC drivers within its server implementations.
Q8: Where can I find the open-source MCP Server for ODBC and MCP SDKs?
A: Model Context Protocol (MCP) Server for ODBC Github Repository and the Model Context Protocol (MCP) Server for SQLAlchemy Github Repository.